LLM Tracing
Quick Summary
LLM tracing allows you to easily debug LLM applications for both production monitoring and development evaluation environments at a component level. You should consider setting up tracing because tracing allows you to easily:
- debug failing test cases (ie. figure out how unsatisfactory
actual_outputs are generated during evaluation). - understand (in real-time) how LLM responses are generated when monitoring in production.
Confident AI is NOT tied to or vendor-locked into any LLM provider or framework, which means you can trace literally any LLM application of your choice.
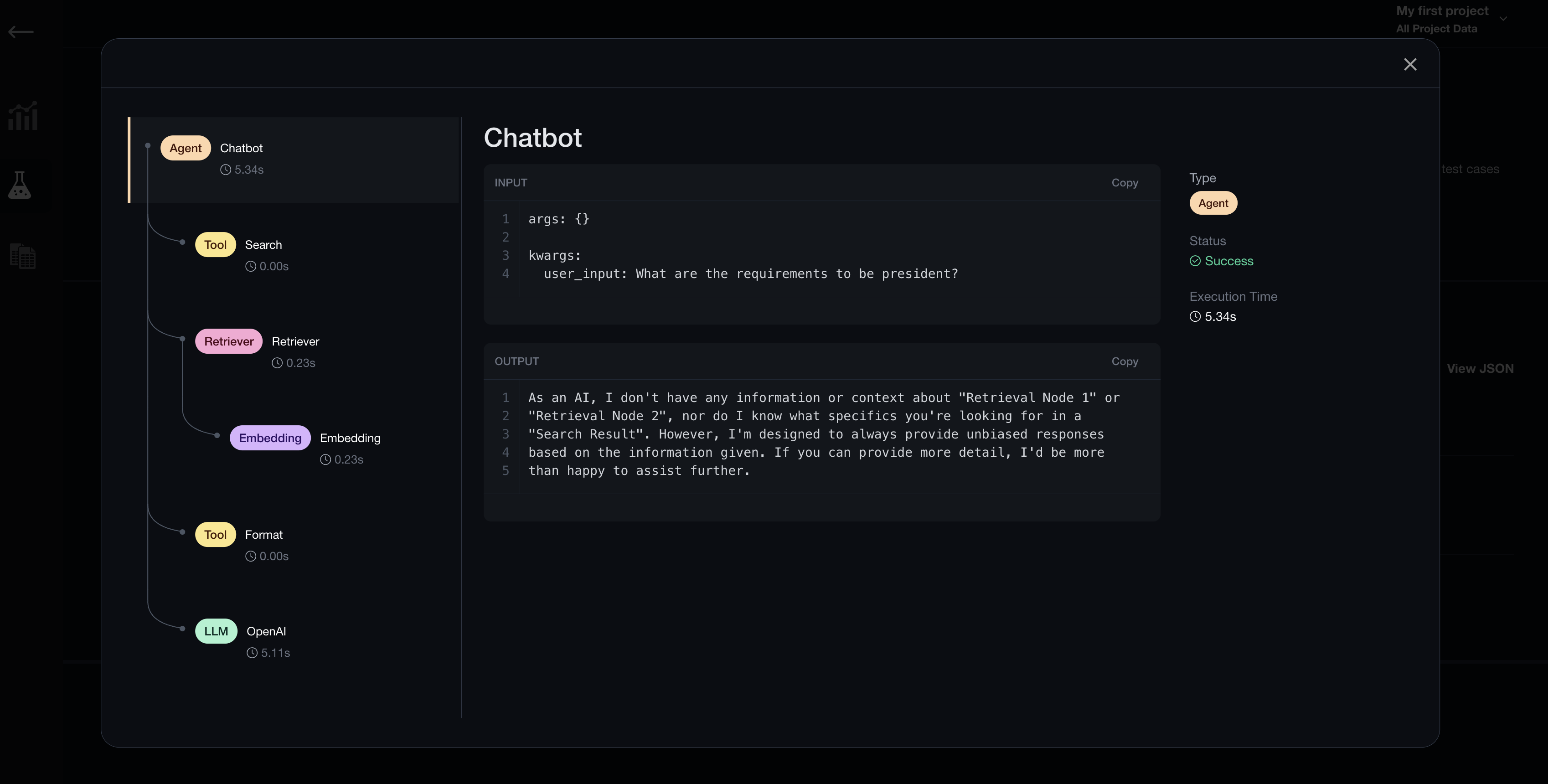
Tracing Integrations
If your LLM application was built using a hybrid approach (eg., a bit of langchain, and bit of llama_index, and maybe a bit of custom LLM API calling), you'll want to consider custom tracing instead.
LlamaIndex
You can setup tracing for LLM applications built with LlamaIndex in 1 line of code:
from llama_index.core import set_global_handler
set_global_handler("deepeval")
The set_global_handler() function tells llama_index to trace via deepeval, which means LLM tracing will automatically be enabled and viewable on Confident AI for each llama_index query:
...
query_engine.query("...")
Setup Custom Tracing
Custom tracing allows you to more flexibly define which part of your LLM application you want traced. There are a two main scenarios where custom tracing comes in handy:
- your LLM application wasn't built on any frameworks
- your LLM applicationi was built on multiple frameworks
In deepeval, tracing a particular component in your LLM application is as simple as adding a with block along with deepeval's Tracer in python.
from deepeval.tracing import Tracer, TraceType
...
with Tracer(trace_type=TraceType.LLM) as llm_trace:
response = openai.ChatCompletion.create(
model='gpt-4o',
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "..."},
],
)
llm_response = response.choices[0].message.content
print(llm_response)
Nesting with blocks in python allows deepeval to recognize the trace hierarchy in your LLM application. For example, this trace structure:
from deepeval.tracing import Tracer, TraceType
with Tracer(trace_type="My LLM Application") as custom_trace:
...
with Tracer(trace_type=TraceType.RETRIEVER) as retriever_trace:
...
with Trace(trace_type=TraceType.EMBEDDING) as embedding_trace:
...
with Tracer(trace_type=TraceType.LLM) as llm_trace:
...
This particular nested with block will give the following structure:
My LLM Application
|
| --- Retriever
| |
| Embedding
|
| --- LLM
*
You'll notice the Tracer accepts a trace_type argument. The trace_type argument accepts either a str (for custom types of traces), or TraceType. The trace_type parameter is an easy way for you to classify components in your LLM pipeline and here are all the TraceTypes that deepeval offers.
TraceType.AGENTTraceType.CHAINTraceType.CHUNKINGTraceType.EMBEDDINGTraceType.LLMTraceType.QUERYTraceType.RERANKINGTraceType.RETRIEVERTraceType.SYNTHESIZETraceType.TOOL
Before the end of some with blocks for some trace_types, as you'll learn later, requires you to call the set_parameters() method to set additional attributes associated with your trace. For example, you'll need to set the model name of the LLM used for an LLM TraceType via the set_parameters() method.
Although you can technically use custom traces for all trace_types to avoid the trouble of setting trace specific attributes, deepeval's default approach provides you with a better UI on Confident AI.
TraceType.LLM
The LLM TraceType should be reserved for components where LLM generation happens.
from deepeval.tracing import Tracer, TraceType, LlmAttributes
...
with Tracer(trace_type=TraceType.LLM) as llm_trace:
response = openai.ChatCompletion.create(
model='gpt-4o',
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "..."},
],
)
llm_response = response.choices[0].message.content
print(llm_response)
# Don't forget to set attributes for the LLM trace type
llm_trace.set_parameters(output=llm_response, metadata=LlmAttributes(model='gpt-4o'))
Additionally, set_attributes() must be called with the following parameters:
attributes: an instance ofLlmAttributescustom_attributes: a custom dictionary to log any additional data associated with the current trace
The LlmAttributes accepts the following arguments:
- [Optional]
model: a string specifying the model name of the LLM used for generation - [Optional]
prompt: a string specifying the input prompt - [Optional]
promptTemplate: a string specifying the prompt template used to construct theprompt - [Optional]
response: a string representing the LLM response generated
TraceType.EMBEDDING
The EMBEDDING TraceType should be reserved for components where text is embedded into its vector representation.
from deepeval.tracing import Tracer, TraceType, EmbeddingAttributes
...
with Tracer(trace_type=TraceType.EMBEDDING) as embedding_trace:
response = openai.embeddings.create(
input="Your text string goes here",
model="text-embedding-3-small"
)
vector = response.data[0].embedding
print(vector)
Additionally, set_parameters() must be called with the following parameters:
attributes: an instance ofEmbeddingAttributescustom_attributes: a custom dictionary to log any additional data associated with the current trace
The EmbeddingAttributes accepts the following arguments:
- [Optional]
model: a string specifying the model name of the embedding model used - [Optional]
input_text: a string specifying the text that was embedded - [Optional]
vector_length: an integer representing the length of the vector
TraceType.RETRIEVER
The RETRIEVER TraceType should be reserved for components where nodes/text chunks/documents are retrieved based based on some vector embedding (as is often the case for RAG applications).
from typing import List
from deepeval.tracing import Tracer, TraceType
...
with Tracer(trace_type=TraceType.RETRIEVER) as retriever_trace:
...
retrieval_nodes : List[str] = get_nodes_in_vector_database(vector)
print(retrieval_nodes)
TraceType.RERANKING
The RERANKING TraceType should be reserved for components where nodes/text chunks/documents are reranked POST retrieval (ie., this should be contained within the RETRIEVER).
from typing import List
from deepeval.tracing import Tracer, TraceType
...
with Tracer(trace_type=TraceType.RERANKING) as reranking_trace:
...
reranked_nodes : List[str] = rerank_nodes(retrieval_nodes)
print(reranked_nodes)
TraceType.SYNTHESIZE
TraceType.TOOL
TraceType.QUERY
TraceType.AGENT
TraceType.CHAIN
Remember, you can also supply a custom str as trace_type for custom trace types.
Tracing During Monitoring in Production
You might also notice that before the return statement in chatbot.query(), we call tool_trace.track() to track each event with the associated trace data. It is absolutely necessary to call this method because your trace data will not be recorded without it. This tracking method has the same exact arguments (and types) as deepeval.track. You can learn more about deepeval.track and tracking events here.
# calling set_parameters before the return statement
def query(self, user_input):
with Tracer(trace_type=TraceType.AGENT) as tool_trace:
...
tool_trace.set_parameters(output)
# you must call tool_trace.track() before returning the output
tool_trace.track(
event_name="Chatbot",
model='gpt-4-turbo-preview',
input=user_input,
response=output,
)
return output
This means that currently, tracing only works if you're tracking evaluations using the track method, and generating actual_outputs from your LLM application at evaluation time (ie. tracing does not work with pre-computed outputs).
LlamaIndex Tracing
deepeval also supports automated tracing for RAG pipelines utilizing LlamaIndex with just a few lines of code. First, import set_global_handler from llama_index.core and set it to ‘deepeval’. Then, define a function to query from your query engine with a custom trace_type using the Tracer with block, and you’re done!
# llama_index pipeline dependencies
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.llms.openai import OpenAI
from llama_index.core import set_global_handler
set_global_handler("deepeval")
# set up your llama_index pipeline
Settings.llm = OpenAI(model="gpt-4-turbo-preview")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
documents = SimpleDirectoryReader("data").load_data()
node_parser = SentenceSplitter(chunk_size=200, chunk_overlap=20)
nodes = node_parser.get_nodes_from_documents(
documents, show_progress=True
)
index = VectorStoreIndex(nodes)
query_engine = index.as_query_engine(similarity_top_k=5)
# define chatbot function with custom trace_type
def chatbot(input):
with Tracer(trace_type="Chatbot") as chatbot_trace:
res = query_engine.query(input).response
chatbot_trace.set_parameters(res)
chatbot_trace.track(
event_name='llama_index chatbot'
input=input,
response=res,
model='gpt-4-turbo-preview',
)
return res
Setup Hybrid Tracing (Custom + LLamaIndex)
Lastly, deepeval supports hybrid tracing, combining custom tracing with LlamaIndex. To do so, set up custom tracing as you normally would. Simply import set_global_handler from llama_index.core and set it to ‘deepeval’. deepeval will handle all the logic behind the scenes and automatically nest the LlamaIndex traces in the correct trace positions.
Here's how you can set it up:
# llama_index dependencies
from llama_index.core.callbacks.base_handler import BaseCallbackHandler
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.embeddings.openai import OpenAIEmbedding
from openai import AsyncOpenAI
from llama_index.core import set_global_handler
set_global_handler("deepeval")
class RAGPipeline:
def __init__(self, model_name="gpt-4-turbo-preview", top_k=5, chunk_size=200, chunk_overlap=20, min_similarity=0.5, data_dir="data"):
openai_key = os.getenv("OPENAI_API_KEY")
if not openai_key:
raise ValueError("OpenAI API key not found in environment variables.")
self.openai_client = AsyncOpenAI(api_key=openai_key)
self.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
documents = SimpleDirectoryReader(data_dir).load_data()
node_parser = SentenceSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
nodes = node_parser.get_nodes_from_documents(documents, show_progress=True)
self.index = VectorStoreIndex(nodes, embed_model=self.embed_model)
self.retriever = self.index.as_retriever(similarity_top_k=top_k, similarity_cutoff=min_similarity)
self.model_name = model_name
def format_nodes(self, query):
with Tracer(trace_type=TraceType.NODE_PARSING) as llama_wrapper_trace:
nodes = self.retriever.retrieve(query)
combined_nodes = "\n".join([node.get_content() for node in nodes])
# set parameters
llama_wrapper_trace.set_parameters(combined_nodes)
return combined_nodes
async def generate_completion(self, prompt, context):
with Tracer(trace_type=TraceType.LLM) as llm_trace:
full_prompt = f"Context: {context}\n\nQuery: {prompt}\n\nResponse:"
response = await self.openai_client.chat.completions.create(
model=self.model_name,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": full_prompt}
],
temperature=0.7,
max_tokens=200
)
output = response.choices[0].message.content
# set parameters
llm_trace.set_parameters(
output=output,
metadata=LlmAttributes(model='gpt-4-turbo-preview')
)
return output
async def aquery(self, query_text):
with Tracer(trace_type=TraceType.QUERY) as query_trace:
context = self.format_nodes(query_text)
response = await self.generate_completion(query_text, context)
# set parameters and track event
query_trace.set_parameters(response)
query_trace.track(
input=query_text,
response=response,
model='gpt-4-turbo-preview',
)
return response